
ما هي هجمات تسمم البيانات؟ وهل يمكن التلاعب بالذكاء الاصطناعي؟

فاجأ التبني السريع لتقنية الذكاء الاصطناعي وإدخال منتجات جديدة للمستخدمين خبراء الذكاء الاصطناعي الذين يحذرون من البيانات الموجودة عبر الويب المستخدمة لتدريب هذه الأدوات، وظهر السؤال: ما مدى فعالية هجمات تسمم البيانات؟
فتحت تقنيات وأدوات الذكاء الاصطناعي التوليدية حِقْبَة جديدة في صناعة التكنولوجيا. يقول الخبراء إنها تعتبر ثورة قادمة. وشبهها البعض بالثورة التي أحدثها ظهور الإنترنت نفسها. لذلك، تتنافس شركات التكنولوجيا الكبرى والشركات الناشئة على توفير التقنيات والمنتجات المناسبة للمرحلة الجديدة من أجل الحصول على حصة في سوق الذكاء الاصطناعي المزدهر.
قدمت كل من مايكروسوفت و جوجل بالفعل إصدارات من روبوتات الدردشة التي تم تطويرها باستخدام نماذج اللغات الكبيرة (LLM) وتعمل حاليًا على دمج هذه الوظيفة في منتجاتها.
ووصل الأمر إلى الحكومة. حيث عينت الحكومة الرومانية روبوت محادثة تفاعلي يسمى (ION) كأول مستشار ذكاء اصطناعي للقيام بواجبات حكومية. يستخدم العلماء برامج الذكاء الاصطناعي للوصول إلى اللغات التي تتحدثها الحيوانات وطريقة تواصلها معها.
لقد فاجأ هذا التبني السريع لتقنية الذكاء الاصطناعي وإدخال منتجات جديدة للمستخدمين خبراء الذكاء الاصطناعي الذين يحذرون من البيانات الموجودة عبر الويب المستخدمة لتدريب هذه الأدوات.
كيف تشكل البيانات على الويب تهديدًا للذكاء الاصطناعي؟

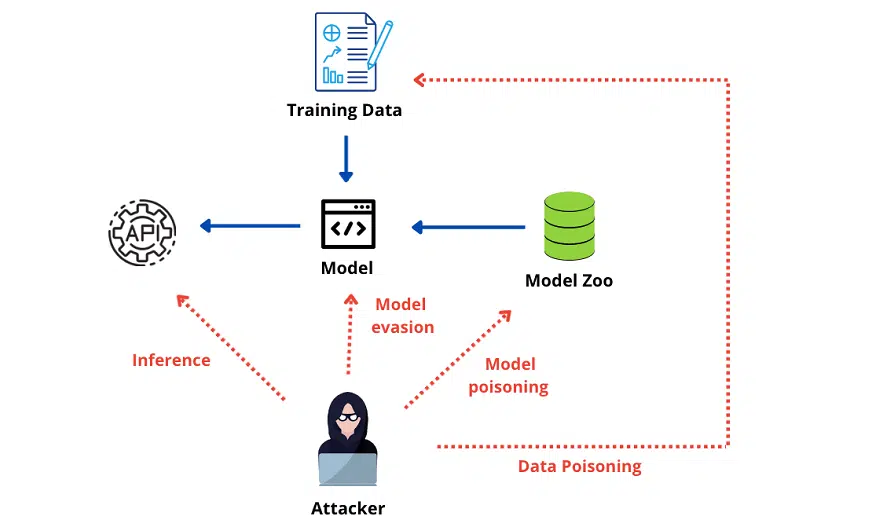
يحذر خبراء الذكاء الاصطناعي والتعلم الآلي من هجمات تسمم البيانات التي يمكن أن تؤثر على مجموعات البيانات الكبيرة المستخدمة بشكل شائع لتدريب نماذج التعلم العميق في العديد من خِدْمَات الذكاء الاصطناعي.
يشير مصطلح (تسمم البيانات) إلى عرض بيانات لا معنى لها أو ضارة بغرض التأثير على أداء نماذج التعلم الآلي وخوارزميات الذكاء الاصطناعي المختلفة التي تعتمد بشكل أساسي على جودة البيانات.
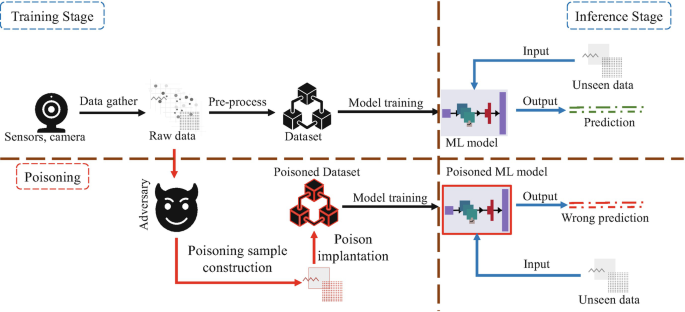
يحدث تسمم البيانات عندما يعدل المهاجم بيانات التدريب المستخدمة لبناء نموذج التعلم العميق. أو خلال مرحلة بناء النموذج، يتلاعب ببيانات الإدخال للتأثير على قرارات الذكاء الاصطناعي بطرق صعبة. ويحدث عندما يمكن أن يؤدي إلى تنبؤات غير دقيقة.
ما مدى فعالية هجمات تسمم البيانات؟

من المحتمل أن تكون هجمات التسمم بالبيانات قوية للغاية. لأن الذكاء الاصطناعي يمكنه التعلم من البيانات الخاطئة واتخاذ قرارات خاطئة ذات عواقب وخيمة بواسطة فعل بسيط للغاية يتمثل في التغيير السري لبيانات المصدر المستخدمة لتدريب خوارزميات التعلم الآلي.
مع أنّ عدم وجود دليل حاليًا على هجوم فعلي ينطوي على تسميم مجموعات البيانات عبر الويب. فقد حددت مجموعة من باحثي الذكاء الاصطناعي والتعلم الآلي في جوجل و NVIDIA و ETH Zurich و Robust Intelligence هجمات تسمم محتملة على الويب. أظهرت مجموعة بيانات أساسية تُستخدم لتدريب نماذج التعلم الآلي الأكثر شيوعًا.
يحذر الباحثون من أنه حتى كَمّيَّة ضئيلة من البيانات المضللة في مجموعة التدريب كافية لإدخال أخطاء مستهدفة في سلوك نموذج الذكاء الاصطناعي.
يقول الباحثون إنهم تمكنوا من تسميم 0.01٪ من مجموعات بيانات التعلم العميق الجيدة بجهد ضئيل. وبتكلفة منخفضة باستخدام تقنية ابتكروها لاستغلال طرق جمع مجموعات البيانات من الويب.

حذر الباحثون من أن 0.01٪ قد تبدو صغيرة جدًا ولا تمثل سوى جزء صغير جدًا من مجموعة البيانات. لكنها كافية لتلويث نموذج ذكاء اصطناعي، وهذا الهجوم هو (تلوث منقسمة العرض). خاصة إذا كنت تتحكم في موارد الويب المفهرسة بواسطة مجموعة معينة من البيانات. فقد تتلف البيانات المجمعة وغير دقيقة، مما يؤثر سلبًا على الخوارزمية الإجمالية.
تشمل هجمات التسمم بالبيانات إعادة كتابة الاتجاهات في لغات روبوتات الدردشة مثل ChatGPT و Bard. وتغيير أساليب التحدث، واستخدام لغة مسيئة لإقناع الخوارزميات بأن بعض الشركات تفعل شيئًا خاطئًا، ومهاجمة الفيروسات والبرامج الضارة. يمكن أخذ عينات منها واستخدامها لإقناع الآخرين بذلك.
تتعلم نماذج الذكاء الاصطناعي مهارات مختلفة لأنواع مختلفة من التطبيقات. وبالتالي فإن الطرق التي يلوث بها المخترقون بيانات تدريبهم واسعة النطاق مثل استخداماتهم.
كيف يمكن تنفيذ هجوم تسمم البيانات؟
تتمثل إحدى الطرق التي يحقق بها المهاجمون هذا الهدف في شراء أسماء نطاقات الإنترنت منتهية الصَّلاحِيَة. والتي تم حصادها لتدريب نماذج الذكاء الاصطناعي، ويمكن أن تلوث الكَمّيَّة الهائلة من البيانات الموجودة.
بالإضافة إلى ذلك، على الرغم من أن المهاجم ليس لديه سيطرة كاملة على مجموعة بيانات معينة. يمكن للباحثين التنبؤ بدقة بموعد وصول المدرب إلى موارد الويب لجمع البيانات لتدريب نماذج الذكاء الاصطناعي. يصف نوعًا ثانيًا من الهجوم يسمى التسمم الأمامي. مما يسمح لها باحتواء بيانات مضللة وتلويث مجموعة البيانات قبل جمعها مباشرة.
حتى إذا عادت المعلومات إلى شكلها الأصلي الذي لم يتم العبث به بعد بضع دقائق فقط. فإن مجموعة البيانات المشوهة التي تم سحبها بواسطة الخوارزمية عندما كان الهجوم الضار نشطًا يتم تخزينها بشكل دائم في النموذج.
ويكيبيديا
استشهد الباحثون بموسوعة ويكيبيديا، وهي واحدة من الموارد المستخدمة بشكل متكرر للحصول على بيانات التدريب للتعلم الآلي، على سبيل المثال. وفقًا للباحثين، يلوث المهاجمون مجموعة التدريب التي توفرها ويكيبيديا بتعديلات ضارة، مما يتسبب في قيام النموذج بجمع بيانات غير دقيقة.
كما تستخدم ويكيبيديا بروتوكولات جمع البيانات الموثقة لتدريب نماذج الذكاء الاصطناعي. وهذا يعني أنه يمكنهم التنبؤ بدقة كبيرة بموعد جمع البيانات من مقالة معينة، والتدخل وتحرير الصفحة بشكل ضار، وإجبار النموذج على جمع بيانات غير دقيقة و مخزنة بشكل دائم في مجموعة البيانات.
كما يعتقد الباحثون أنه يمكن إساءة استخدام البروتوكول لتسميم صفحات ويكيبيديا بمعدل نجاح يصل إلى 6.5٪. قد لا تبدو هذه النسبة عالية.
ومع ذلك، فإن العدد الهائل من الصفحات على ويكيبيديا والطريقة التي يتم استخدامها بها لتدريب مجموعات بيانات التعلم الآلي تعني أنها يمكن أن تقدم معلومات غير دقيقة للعديد من النماذج.
يحذر الباحثون ويكيبيديا من الهجمات والدفاعات المحتملة، والغرض من نشر الورقة هو تزويد الآخرين في المجال الأمني بأفكارهم الخاصة حول طريقة الدفاع عن أنظمة الذكاء الاصطناعي والتعلم الآلي ضد الهجمات الخبيثة.
وقالوا “عملنا هو مجرد نقطة انطلاق للمجتمع لفهم أفضل للمخاطر التي ينطوي عليها إنشاء النماذج من البيانات الموجودة عبر الويب”.
شرح خطورة الـ Bluebugging وطريقة الوقاية من مخاطر البلوتوث
في النهاية، ما هي الحلول؟
ومن المثير للاهتمام، أن التلاعب بنماذج الذكاء الاصطناعي بهذه الطريقة يفضح المشكلات التي واجهها متخصصو الأمن السيبراني في قضايا تدريب الموظفين. وغالبًا ما يكون المهاجمون غير مدربين بواسطة استهداف الموظفين بحيل التصيد الاحتيالي. واعتمدوا على عدم وعي الموظفين للتسلل إلى الشركة، وينطبق هذا أيضًا على تسميم بيانات الذكاء الاصطناعي.

لا يزال متخصصو الأمن السيبراني في مراحله المبكرة، ويتعلمون طريقة الدفاع ضد هجمات تسمم البيانات بأفضل طريقة ممكنة. كما يشير بلوم برج إلى أن إحدى طرق منع التسمم بالبيانات هي جعل العلماء يطورون نماذج ذكاء اصطناعي يتحققون بانتظام من صحة جميع الملصقات في بيانات التدريب الخاصة بهم.
نجح متخصصون آخرون أيضًا في استخدام البيانات مفتوحة المصدر بحكمة، على الرغم من فوائدها، لأنها توفر الوصول إلى المزيد من البيانات لإثراء المصادر الحالية. هذا يعني أنه من الأسهل تطوير نماذج أكثر دقة، ولكنه أيضًا يجعل النموذج المدرب هدفًا أسهل للمحتالين والمتسللين.
يمكن أن يوفر اختبار الاختراق أيضًا حلاً لأنه يمكنه العثور على نِقَاط الضعف التي تسمح للقراصنة بالوصول إلى نماذج التدريب في بياناتك. كما يفكر بعض الباحثين أيضًا في تطوير طبقة ثانية من الذكاء الاصطناعي والتعلم الآلي المصممة لتحديد الأخطاء المحتملة في بيانات التدريب.
لقد جلب الذكاء الاصطناعي بلا شك العديد من الفوائد للعالم، ولكن يمكن للقراصنة أن يمروا دون أن يلاحظهم أحد داخل تكنولوجيا المعلومات التي يستهدفونها. مما يجعل من الصعب اكتشاف الهجمات بل ويصعب إحباطها. ولأنه يزداد صعوبة، فإنه يثير أيضًا مخاوف أمنية خطيرة. تتيح التطورات في تقنيات الذكاء الاصطناعي والتعلم الآلي للقراصنة الوصول إلى قواعد البيانات الضخمة والتحكم في استخراج البيانات.
في حين أن هذا قد لا يشكل تهديدًا كبيرًا للأفراد، إلا أنه يمكن أن يكون مشكلة أمنية على المستوى العالمي. مع الأخذ في الاعتبار أن التنقيب عن البيانات يتم تطبيقه في العديد من المجالات. أهمها الأسواق المالية الرئيسة والقطاع الصحي. الرعاية، وغيرها من المجالات الحرجة.
شرح طريقة تجريف موقع الويب وإستخراج أي بيانات ترغب بها بإستخدام التطبيقات




2 تعليقات