

Pandas هي مكتبة مجموعات البيانات والأطر الأكثر شيوعًا. هذا معيار قديم. ومع ذلك، مع تطور الذكاء الاصطناعي، تم تطوير مكتبة جديدة مفتوحة المصدر تسمى PandasAI والتي تضيف قدرات الذكاء الاصطناعي التوليدية إلى Pandas.
PandasAI ليس بديلاً عن الباندا. بدلاً من ذلك، يتم منحها قدرات الذكاء الاصطناعي التوليدية. بهذه الطريقة، يمكنك إجراء تحليل للبيانات من خلال التحدث إلى PandasAI. ثم يلخص ما يحدث في الخلفية ويقدم نتائج الطلب.
1- طريقة تثبيت PandasAI
يتوفر PandasAI من خلال PyPI (فهرس حزمة بايثون). إذا كنت تستخدم IDE المحلي الخاص بك، فيمكنك البدء بإنشاء بيئة افتراضية جديدة. ثم قم بتثبيتها باستخدام مدير حزم PiP.
pip install pandasai
إذا كنت تستخدم جوجل كولاب، فقد تحصل على خطأ تعارض التبعية كما هو موضح أدناه.
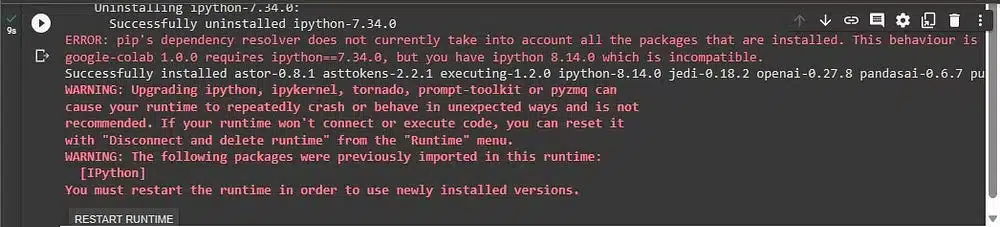
لا تقم بالرجوع إلى إصدار أقدم من IPython. ما عليك سوى إعادة تشغيل وقت التشغيل وتشغيل كتلة التعليمات البرمجية مرة أخرى. ثم سيتم حل المشكلة.
كود المصدر الكامل متاح في مستودع جيتهب.
2- فهم نماذج مجموعات البيانات
مجموعة البيانات النموذجية التي نستخدمها مع PandasAI هي مجموعة بيانات Kaggle’s California House Price. تحتوي مجموعة البيانات هذه على معلومات الإسكان من تعداد كاليفورنيا لعام 1990. يحتوي على 10 أعمدة توفر إحصائيات عن هذه المنازل. تتوفر ورقة بيانات لمساعدتك في معرفة المزيد حول مجموعة البيانات هذه على Kaggle. فيما يلي الصفوف الخمسة الأولى من مجموعة البيانات:

يمثل كل عمود إحصائية واحدة للمنزل.
3- طريقة ربط PandasAI بنماذج اللغات الكبيرة
لتوصيل PandasAI بنموذج لغة كبير (LLM) مثل نموذج OpenAI، تحتاج إلى الوصول إلى مفتاح API الخاص به. للحصول على مفتاحك، انتقل إلى منصة OpenAI. ثم قم بتسجيل الدخول إلى حسابك. حدد واجهات برمجة التطبيقات في صفحة الإعدادات التي تظهر.

ثم انقر فوق ملف التعريف الخاص بك وحدد الخيار لعرض مفتاح API الخاص بك. في الصفحة التالية، انقر فوق الزر “إنشاء مفتاح خاص جديد”. أخيرًا، قم بتسمية مفتاح API الخاص بك.
سيقوم OpenAI بإنشاء مفتاح API لك. انسخه إلى المكان الذي تريده عند توصيل PandasAI بـ OpenAI. احتفظ بمفتاحك الخاص آمنًا حتى يتمكن أي شخص لديه حق الوصول إليه من الاتصال بـ OpenAI نيابة عنك. كما ستقوم OpenAI بفواتير حسابك وفقًا لعدد المطالبات.
الآن بعد أن أصبح لديك مفتاح API الخاص بك، قم بإنشاء نص برمجي جديد من بايثون والصق الكود أدناه. في معظم الحالات، تعتمد متطلباتك على هذا الرمز، لذا لن تحتاج إلى تغيير هذا الرمز.
import pandas as pd from pandasai import PandasAI # Replace with your dataset or dataframe df = pd.read_csv(“/content/housing.csv”) # Instantiate a LLM from pandasai.llm.openai import OpenAI llm = OpenAI(api_token=”your API token”) pandas_ai = PandasAI(llm)
يستورد الرمز أعلاه كلاً من PandasAI و Pandas. ثم اقرأ مجموعة البيانات. أخيرًا، نرى OpenAI LLM.
أنت الآن جاهز للعمل مع بياناتك. راجع أيضا أفضل 7 مستودعات GitHub لتعلم لغة بايثون بسهولة!
4- طريقة أداء مهام بسيطة مع PandasAI
للاستعلام عن البيانات، نطلب مثيلًا لفئة PandasAI، لتمريرها إلى إطار بيانات. أولاً، تحقق من الصفوف الخمسة الأولى من مجموعة البيانات.
pandas_ai(df, prompt=’What are the first five rows of the dataset?’)
سيكون ناتج البيان أعلاه:

هذا الإخراج هو نفسه الناتج السابق في مراجعة نموذج مجموعة البيانات. وهذا يدل على أن PandasAI قدمت نتائج صحيحة وموثوقة.
ثم تحقق من عدد الأعمدة في مجموعة البيانات:
pandas_ai(df, prompt=’How many columns are in the dataset? ‘)
تُرجع 10، وهو العدد الصحيح من الأعمدة لمجموعة بيانات منازل كاليفورنيا.
تحقق مما إذا كانت مجموعة البيانات تحتوي على قيم مفقودة:
pandas_ai(df, prompt=’Are there any missing values in the dataset?’)
ترجع مكتبة باندا المدعومة بالذكاء الاصطناعي التوليدي أن هناك 207 قيمة مفقودة في عمود total_bedrooms، وهذا صحيح أيضًا.
هناك العديد من المهام البسيطة التي يمكنك القيام بها مع PandasAI، لكنك لست مقيدًا بالمهام المذكورة أعلاه.
5- قم بتشغيل استعلامات معقدة باستخدام PandasAI
يدعم PandasAI أكثر من المهام البسيطة. يمكنك أيضًا استخدامه لتشغيل استعلامات معقدة في مجموعات البيانات. على سبيل المثال، إذا كانت لديك مجموعة بيانات الإسكان وتريد تحديد عدد المنازل التي يزيد سعرها عن 100 ألف دولار أمريكي وأكثر من 10 غرف، يمكنك استخدام النصائح التالية.
pandas_ai(df,prompt= “How many houses have a value greater than 100000,” “ are in an island and total bedrooms is more than 10?”)
هناك 5 إجابات صحيحة. هذه هي نفس نتيجة PandasAI.
يمكن أن تستغرق نتائج الاستعلام المعقدة وقتًا طويلاً لإنشاء محللي البيانات وتصحيحهم. تتطلب النصيحة أعلاه سطرين فقط من اللغة الطبيعية لإكمال نفس المهمة. ما عليك سوى أن تتذكر بالضبط ما تريد تحقيقه وسوف تهتم PandasAI بالباقي. تحقق من ما هي أفضل مكتبة بايثون تستخدم في الذكاء الاصطناعي؟
6- طريقة رسم المخططات باستخدام PandasAI
الرسوم البيانية هي جزء مهم من أي عملية تحليل البيانات. يساعد محللي البيانات على تصور البيانات بطريقة صديقة للإنسان. لدى PandasAI أيضًا وظيفة رسم
ما عليك سوى تمرير إطار البيانات والتعليمات.
أولاً، قم بإنشاء رسم بياني لكل عمود في مجموعة البيانات الخاصة بك. هذا يساعد على تصور توزيع المتغيرات.
pandas_ai(df, prompt= “Plot a histogram for each column in the dataset”)
تبدو النتيجة كما يلي:
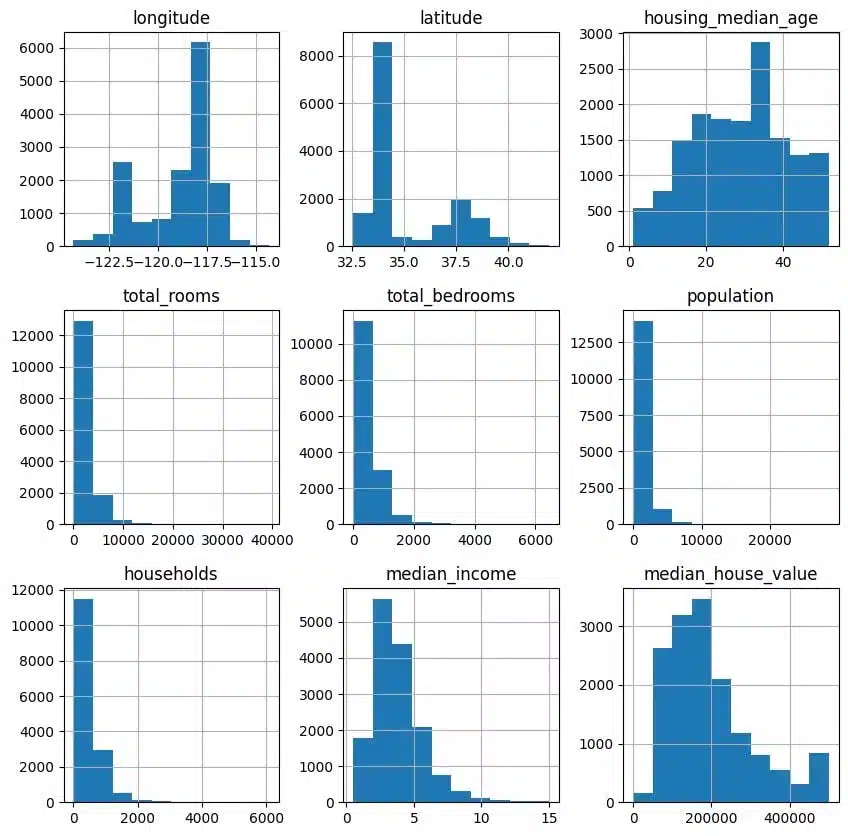
تمكنت مكتبة باندا المدعومة بالذكاء الاصطناعي التوليدي من بناء جميع الأعمدة دون تمرير أسمائها إلى تلميح الأدوات.
يمكن لـ PandasAI أيضًا رسم الرسوم البيانية دون تحديد أي منها يجب استخدامه. على سبيل المثال، قد ترغب في معرفة ارتباط البيانات في مجموعة بيانات الإسكان الخاصة بك. للقيام بذلك، قم بتقديم مطالبة على النحو التالي:
pandas_ai(df, prompt= “Plot the correlation in the dataset”)
يرسم PandasAI مصفوفة ارتباط كما هو موضح في الصورة التالية:
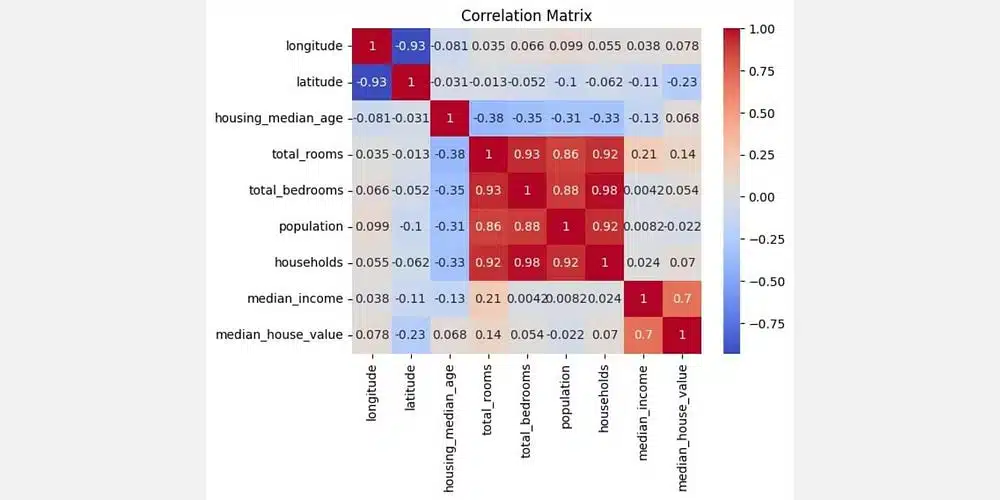
تختار المكتبة خريطة الحرارة وترسم مصفوفة الارتباط.
7- تمرير إطارات بيانات متعددة إلى باندا
قد تكون معالجة إطارات البيانات المتعددة صعبة. خاصة بالنسبة لأولئك الجدد على تحليل البيانات. تملأ مكتبة باندا المدعومة بالذكاء الاصطناعي التوليدي هذه الفجوة من خلال السماح لك ببساطة بتمرير كل إطار بيانات ومعالجة البيانات باستخدام التلميحات.
إنشاء اثنين من إطارات البيانات في Pandas:
employees_data = {
‘EmployeeID’: [1, 2, 3, 4, 5],
‘Name’: [‘John’, ‘Emma’, ‘Liam’, ‘Olivia’, ‘William’],
‘Department’: [‘HR’, ‘Sales’, ‘IT’, ‘Marketing’, ‘Finance’]
}
salaries_data = {
‘EmployeeID’: [1, 2, 3, 4, 5],
‘Salary’: [5000, 6000, 4500, 4000, 5500]
}
employees_df = pd.DataFrame(employees_data)
salaries_df = pd.DataFrame(salaries_data)
يمكن أن تطرح على PandasAI أسئلة تتضمن كل إطار بيانات. ما عليك سوى تمرير كلا إطارات البيانات إلى مثيل PandasAI الخاص بك.
pandas_ai([employees_df, salaries_df], “Which employee has the largest salary?”)
لقد أعادت قيمة Emma، وهذا صحيح أيضًا.
لم يكن تحليل البيانات أسهل من أي وقت مضى. حيث يتيح PandasAI توصيل البيانات وتحليلها بسهولة.
افهم التكنولوجيا الكامنة وراء مكتبة باندا المدعومة بالذكاء الاصطناعي التوليدي
يبسط PandasAI عملية تحليل البيانات ويوفر الكثير من الوقت لمحللي البيانات. لكن هذا يلخص ما يحدث في الخلفية. لفهم طريقة عمل مكتبة باندا المدعومة بالذكاء الاصطناعي التوليدي تحت الغطاء، تحتاج إلى التعرف على الذكاء الاصطناعي التوليدي. كما أنه يساعدك على إطلاعك على أحدث الابتكارات في مجال الذكاء الاصطناعي التوليدي.



