

في أغسطس 2023، أعلنت شركة OpenAI، وهي شركة ذكاء اصطناعي قوية معروفة بتطوير ChatGPT والعديد من النماذج المتقدمة الأخرى، عن GTBot، وهو زاحف ويب مصمم لاستخراج الإنترنت وجمع البيانات.
بعد وقت قصير من هذا الإعلان، قامت بعض أكبر المواقع على الإنترنت بحظر برامج الزحف من الوصول إلى مواقعها. لكن لماذا؟ ما هو GTBot OpenAI ولماذا تخاف منه المواقع الكبرى ولماذا يحاولون حظره؟
ما هو GTBot الخاص بـ OpenAI؟
GTBot هو زاحف ويب تم إنشاؤه بواسطة OpenAI للبحث في الإنترنت وجمع المعلومات بغرض تطوير نماذج الذكاء الاصطناعي OpenAI. تمت برمجته للزحف إلى مواقع الويب العامة وإرسال البيانات المجمعة إلى خوادم OpenAI.
حيث يستخدم OpenAI هذه البيانات لتدريب نماذج الذكاء الاصطناعي وتحسينها لإنشاء أنظمة ذكاء اصطناعي أكثر تقدمًا وتفصيلاً. إن روبوتات الزحف على الويب مطلوبة تقريبًا للوصول إلى التقنيات المتقدمة مثل GPT-4 وChatGPT.
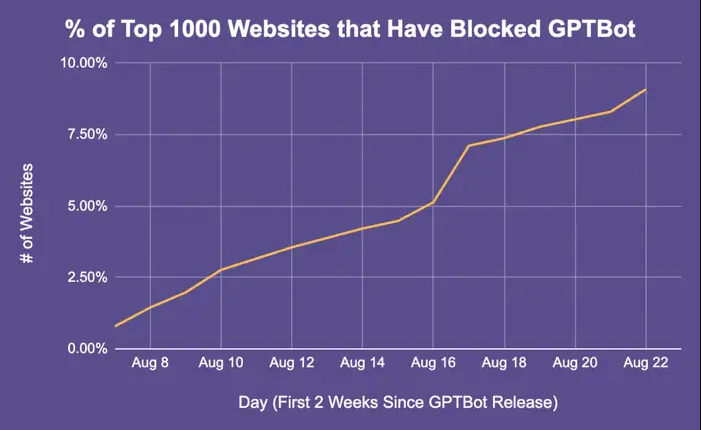
يتطلب تدريب نماذج الذكاء الاصطناعي كميات هائلة من البيانات، وإحدى أكثر الطرق فعالية لجمع هذه البيانات هي نشر أدوات مثل GTBot. يمكنه الزحف بشكل منهجي إلى الإنترنت، واتباع الروابط، وفهرسة أعداد كبيرة من صفحات الويب، واستخراج البيانات الأساسية مثل النصوص والصور والبيانات الوصفية التي تطابق الأنماط المحددة مسبقًا.
يمكن تنظيم هذه البيانات وإدخالها في نماذج الذكاء الاصطناعي، والتي يمكن تدريبها على معالجة اللغة الطبيعية، أو قدرات توليد الصور، أو مهام الذكاء الاصطناعي الأخرى. لتبسيط الأمر، تقوم الروبوتات التي تزحف إلى صفحات الويب بجمع البيانات التي تسمح لأدوات مثل ChatGPT وDALL-E بالقيام بذلك.
إن الروبوتات التي تزحف عبر صفحات الويب ليست مفهومًا جديدًا. من المحتمل أن يكون هناك الملايين من المستخدمين الذين يقومون بالفعل بالزحف إلى مليارات المواقع المتوفرة حاليًا على الإنترنت. لقد كان هذا موجودًا منذ أوائل التسعينيات على الأقل. GTBot هو أحد روبوتات المسح المملوكة لشركة OpenAI. فلماذا يسبب زاحف الويب هذا الكثير من الجدل؟
لماذا تقوم مواقع التكنولوجيا الكبرى بحظر GTBot؟
وفقًا لموقع Business Insider، تحظر بعض مواقع الويب الرئيسية برامج زحف OpenAI لمنع الوصول إلى محتواها. فإذا كان الهدف النهائي لـ GTBot هو تسريع تطوير الذكاء الاصطناعي، فلماذا تعارض بعض أكبر المواقع على الإنترنت التي تستفيد منه بطريقة أو بأخرى GTBot؟

حسنا، هذا ما نتحدث عنه. في عام 2022، كان هناك الكثير من النقاش حول حقوق شركات الذكاء الاصطناعي في استخدام البيانات التي تم الحصول عليها من الإنترنت، والتي يتمتع الكثير منها بحماية قانون حقوق الطبع والنشر. لا توجد قوانين واضحة تحكم طريقة قيام الشركات بجمع البيانات واستخدامها لمصلحتها الخاصة.
لذا فإن الروبوتات الزاحفة مثل GTBot يمكنها في الأساس الوصول إلى المعلومات المتاحة على الإنترنت، واسترداد الأعمال الإبداعية للأشخاص في هيئة نصوص وصور وأشكال أخرى من الوسائط، واسترداد الإبداع الأصلي. واستخدامها لأغراض تجارية دون إذن أو ترخيص أو تعويض. إلى أي طرف ثالث..
إنها حالة من افتراس الأقوياء للضعفاء، وشركات الذكاء الاصطناعي التي تأخذ كل ما في وسعها للحصول عليه. مواقع الويب الكبرى مثل Quora وCNN وThe New York Times وBusiness Insider وAmazon ليست سعيدة جدًا بحذف محتواها المحمي بحقوق الطبع والنشر بواسطة برامج الزحف هذه. لأن OpenAI من المحتمل أن تستفيد ماليًا من موقع الويب دون تلقي أي إيرادات منه.
ولذلك، يتم حظر مواقع الويب هذه باستخدام ملف “robots.txt”. هذه طريقة مجربة منذ عقود من الزمن لمنع الروبوتات من الزحف إلى صفحات الويب الخاصة بك. وفقًا لـ OpenAI، يتبع GTBot تعليمات الزحف إلى موقع ويب أو تجنب الزحف إليه بناءً على القواعد الموجودة في ملف robots.txt. ملف robots.txt هو ملف نصي صغير يخبر برامج الزحف بما يجب فعله على موقع الويب الخاص بك. تحقق من شرح ChatGPT Enterprise الموجه خصيصًا للمؤسسات

هل يمكن لمواقع الويب أن توقف جي تي بوت حقًا؟
تعد الروبوتات الزاحفة مثل GTBot ضرورية لجمع كميات كبيرة من البيانات اللازمة لتدريب أنظمة الذكاء الاصطناعي المتقدمة. ولكن هناك مخاوف مشروعة بشأن حقوق النشر والاستخدام العادل والتي لا يمكن تجاهلها.
بالطبع، هناك أدوات بسيطة مثل ملف robots.txt يمكن استخدامها للحماية من التهديدات المحتملة، لكن الأمر لا يزال صعبًا.



